Notes from https://uvadlc-notebooks.readthedocs.io/en/latest/tutorial_notebooks/tutorial6/Transformers_and_MHAttention.html
## Standard Librariesimport osfrom tracemalloc import Snapshotimport numpy as numpyimport randomimport mathimport jsonfrom functools import partialimport loggingimport sys# imports for plottingimport matplotlib.pyplot as pltimport matplotlib_inlineplt.set_cmap('cividis')%matplotlib inlinematplotlib_inline.backend_inline.set_matplotlib_formats()from matplotlib.colors import to_rgbimport matplotlibmatplotlib.rcParams['lines.linewidth'] =2.0import seaborn as snssns.reset_orig()from tqdm.notebook import tqdm# pytorchimport torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimimport torchvisionfrom torchvision import transformsimport pytorch_lightning as plfrom pytorch_lightning.callbacks import LearningRateMonitor, ModelCheckpoint# othersimport einops# path to folder where datasets should be downloadedDATASET_PATH ="../data"CHECKPOINT_PATH ="../saved_models"# setting the seedpl.seed_everything(42)# Ensure that all operations are deterministirc on GPUtorch.backends.cudnn.deterministic =Truetorch.backends.cudnn.benchmark =Falselogging.basicConfig(stream=sys.stdout, level=logging.INFO)logger = logging.getLogger(__name__)device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")print("Device: ", device)
Global seed set to 42
Device: cpu
What is Attention?
The attention mechanism describes a weighted average of sequence of elements with the weights dynamically computed based on the input query and the element’s keys.
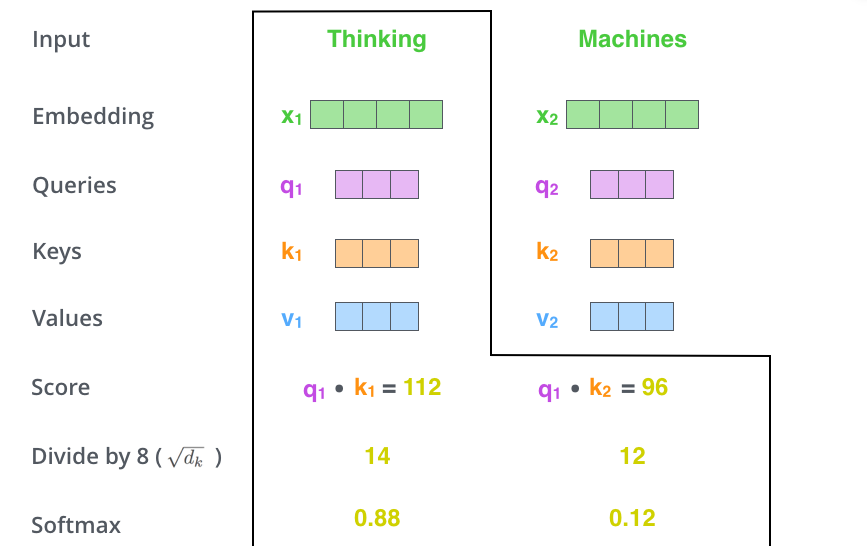
As we can see above, Query, Key and Value are all just modified word embedding.
image
(image from http://jalammar.github.io/illustrated-transformer/) #### Self-attention We use self-attention to modify each embedding of the input word as a combination of modified values from the word embedding and the weights computed. Some intuitions
Values are nothing but modified word embeddings which will be weighted and given as outputs
Query is the modified word embedding which will search for relevant word embeddings in the sequence
Keys are modified word embeddings which will be searched by the query to create the weights
As we are using dot product, we are essentially computing the cosine similarity between the query and the key. The higher the cosine similarity, the higher the weight.
If we look at the softmax scores, clearly the word at its own position will have the highest softmax score, but sometimes it’s useful to attend to another word that is relevant to the current word.
Lets look at the statement The animal didn't cross the street because it was too tired. In this case, softmax for ‘it’ will have a parts of itself, animal (more) and street (less)
In addition to attending to other parts of sentence, the softmax can also drown out the irrelvant words by multiplying them with a very small number.
image
Multi Head Attention
An attention layer outputs a representation of the input sequence, based on the weights learnt for Query, Key and Value. We use multiple heads and combine them using a linear layer to get a better representation of the input sequence.
class EncoderBlock(nn.Module):def__init__(self, input_dim, num_heads, dim_feedforward, dropout=0.0):super().__init__()# attention layerself.self_attn = MultiHeadAttention(input_dim, input_dim, num_heads)# two layer MLPself.linear_net = nn.Sequential( nn.Linear(input_dim, dim_feedforward), nn.Dropout(dropout), nn.ReLU(inplace=True), nn.Linear(dim_feedforward, input_dim) )# layers to apply inbetween main layersself.norm1 = nn.LayerNorm(input_dim)self.norm2 = nn.LayerNorm(input_dim)self.dropout = nn.Dropout(dropout)def forward(self, x, mask=None):# Attention part attn_out =self.self_attn(x, mask=mask) x = x +self.dropout(attn_out) x =self.norm1(x)# MLP part linear_out =self.linear_net(x) x = x +self.dropout(linear_out) x =self.norm2(x)return xclass TransformerEncoder(nn.Module):def__init__(self, num_layers, **block_args):super().__init__()self.layers = nn.ModuleList([EncoderBlock(**block_args) for _ inrange(num_layers)])def forward(self, x, mask=None):for l inself.layers: x = l(x, mask=mask)return xdef get_attention_maps(self, x, mask=None): attention_maps = []for l inself.layers: _, attn_map = l.self_attn(x, mask=mask, return_attention=True) attention_maps.append(attn_map) x = l(x)return attention_mapsclass PositionalEncoding(nn.Module):def__init__(self, d_model, max_len=5000):super().__init__()# create a matrix of seq_len, hidden_dim representing the positinal encoding for pe = torch.zeros(max_len, d_model)# position is index of the word in the sequence position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) div_term = torch.exp(torch.arange(0, d_model, 2)) *-math.log(10000)/d_model pe[:, 0::2] = torch.sin(position * div_term) pe[:, 1::2] = torch.cos(position * div_term) pe = pe.unsqueeze(0)# register_buffer => tensor which is not a parameter, but shold be a part of the modules state# used for tensors that need to be on the same device as the module# persistent=False tell pytorch not to add the buffer to the state_dictself.register_buffer('pe', pe, persistent=False)def forward(self, x): x = x +self.pe[:, :x.size(1)]return x
\[
f(n) =
\begin{cases}
n/2, & \text{if $n$ is even} \\
3n+1, & \text{if $n$ is odd}
\end{cases}
\]
Positional Encoding
We add a fixed signal (not trainable) to each word based on its position. The dimension of the PE signal is same is same as the word dimension.
Here pos is the word position and i is the embedding position.
For a deeper intuition, look at - https://kazemnejad.com/blog/transformer_architecture_positional_encoding/ - https://towardsdatascience.com/master-positional-encoding-part-i-63c05d90a0c3
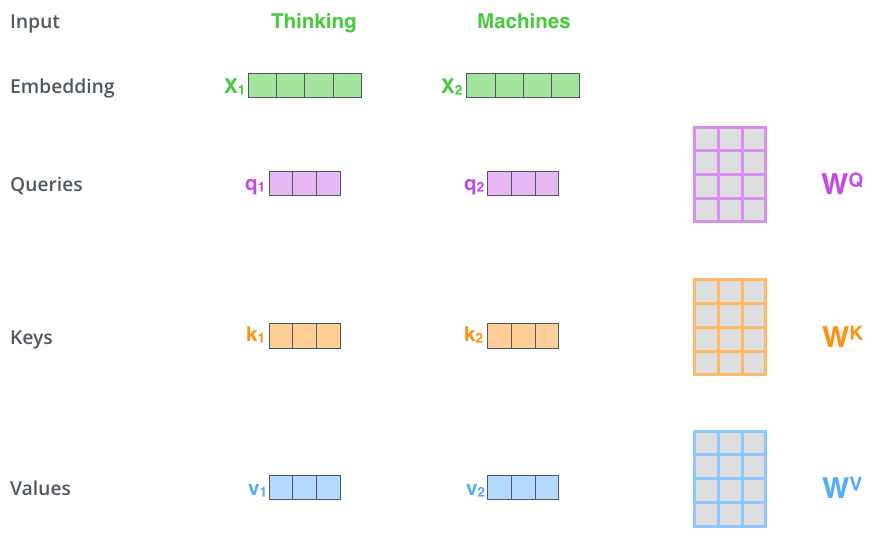 As we can see above, Query, Key and Value are all just modified word embedding.
As we can see above, Query, Key and Value are all just modified word embedding.